Feature selection is an important step for practical commercial data mining which is often characterised by data sets with far too many variables for model building. There are two main approaches to selecting the features (variables) we will use for the analysis: the minimal-optimal feature selection which identifies a small (ideally minimal) set of variables that gives the best possible classification result (for a class of classification models) and the all-relevant feature selection which identifies all variables that are in some circumstances relevant for the classification.
In this article we take a first look at the problem of all-relevant feature selection using the Boruta package by Miron B. Kursa and Witold R. Rudnicki. This package is developed for the R statistical computing and analysis platform.
Background
All-relevant feature selection is extremely useful for commercial data miners. We deploy it when we want to understand the mechanisms behind the behaviour or subject of interest, rather than just building a black-box predictive model. This understanding leads us to a better appreciation of our customers (or other subject under investigation) and not just how, but why they behave as they do, which is useful for all areas of the business, including strategy and product development. More narrowly, it also help us define the variables that we want to observe which is what will really make a difference in our ability to predict behaviour (as opposed to, say, run the data mining application a little longer).
I really like the theoretical approach that the Boruta package tries to implement. It is based on the more general idea that by adding randomness to a system and then collecting results from random samples of the bigger system, one can actually reduce the misleading impact of randomness in the original sample.
For the implementation, the Boruta package relies on a random forest classification algorithm. This provides an intrinsic measure of the importance of each feature, known as the Z score. While this score is not directly a statistical measure of the significance of the feature, we can compare it to random permutations of (a selection of) the variables to test if it is higher than the scores from random variables. This is the essence of the implementation in Boruta.
The tests
This article is a first investigation into the performance of the Boruta package. For this initial examination we will use a test data sample that we can control so we know what is important and what is not. We will consider 200 observations of 20 normally distributed random variables:
run.name <- "feature-1"
library("Boruta")
set.seed(1)
## Set up artificial test data for our analysis
n.var <- 20
n.obs <- 200
x <- data.frame(V=matrix(rnorm(n.var*n.obs), n.obs, n.var))Normal distribution has the advantage of simplicity, but for commercial application where highly non-normally distributed features like money spent are important may not be the best test. Nevertheless, we will use it for now and define a simple utility function before we get on to the tests:
## Utility function to make plots of Boruta test results
make.plots <- function(b, num,
true.var = NA,
main = paste("Boruta feature selection for test", num)) {
write.text <- function(b, true.var) {
if ( !is.na(true.var) ) {
text(1, max(attStats(b)$meanZ), pos = 4,
labels = paste("True vars are V.1-V.",
true.var, sep = ""))
}
}
plot(b, main = main, las = 3, xlab = "")
write.text(b, true.var)
png(paste(run.name, num, "png", sep = "."), width = 8, height = 8,
units = "cm", res = 300, pointsize = 4)
plot(b, main = main, lwd = 0.5, las = 3, xlab = "")
write.text(b, true.var)
dev.off()
}Test 1: Simple test of single significant variable
For a simple classification based on a single variable, Boruta performs well: while it identifies three variables as being potentially important, this does include the true variable (V.1) and the plot clearly shows it as being by far the most significant.
## 1. Simple test of single variable
y.1 <- factor( ifelse( x$V.1 >= 0, 'A', 'B' ) )
b.1 <- Boruta(x, y.1, doTrace = 2)
make.plots(b.1, 1)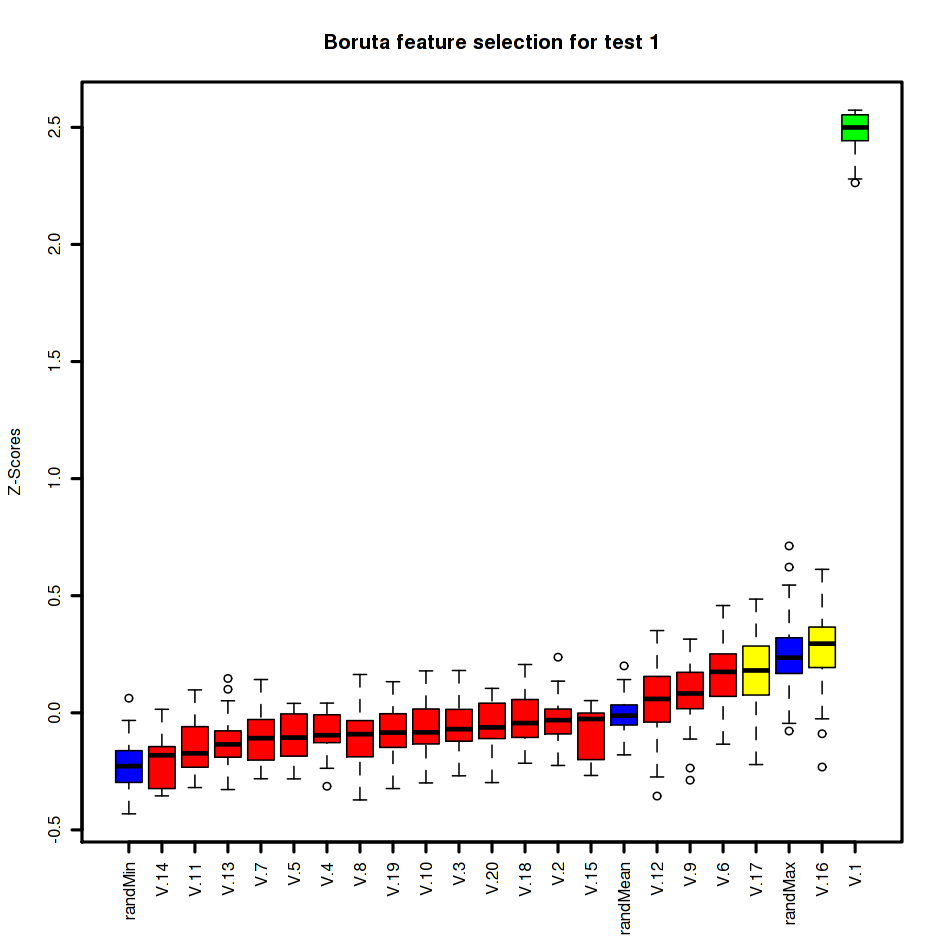
Test 2: Simple test of linear combination of variables
With a test of a linear combination of the first four variables where the weights are decreasing from 4 to 1, we begin to get closer to the limitations of the approach.
## 2. Simple test of linear combination
n.dep <- floor(n.var/5)
print(n.dep)
m <- diag(n.dep:1)
y.2 <- ifelse( rowSums(as.matrix(x[, 1:n.dep]) %*% m) >= 0, "A", "B" )
y.2 <- factor(y.2)
b.2 <- Boruta(x, y.2, doTrace = 2)
make.plots(b.2, 2, n.dep)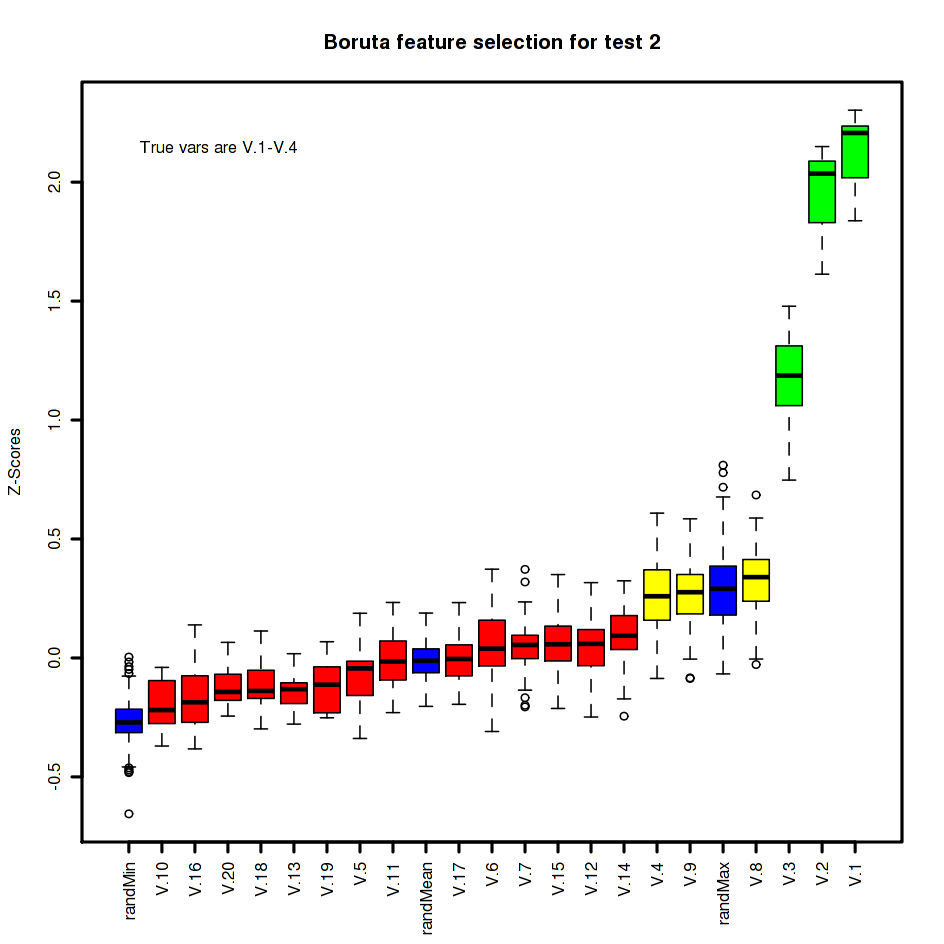
The implementation correctly identified the first three variables (with weights 4, 3, and 2, respectively) as being important, but it had the fourth variable as possible along with the two random variables V.8 and V.9. Still, six variables are more approachable than twenty.
Test 3: Simple test of less-linear combination of four variables
For this text and the following we consider less obvious combinations of the first four variables. If we just count how many of them are positive, then we get to a situation where Boruta excels (because random forests excel at this type of problem).
## 3. Simple test of less-linear combination
y.3 <- factor(rowSums(x[, 1:n.dep] >= 0))
print(summary(y.3))
b.3 <- Boruta(x, y.3, doTrace = 2)
print(b.3)
make.plots(b.3, 3, n.dep)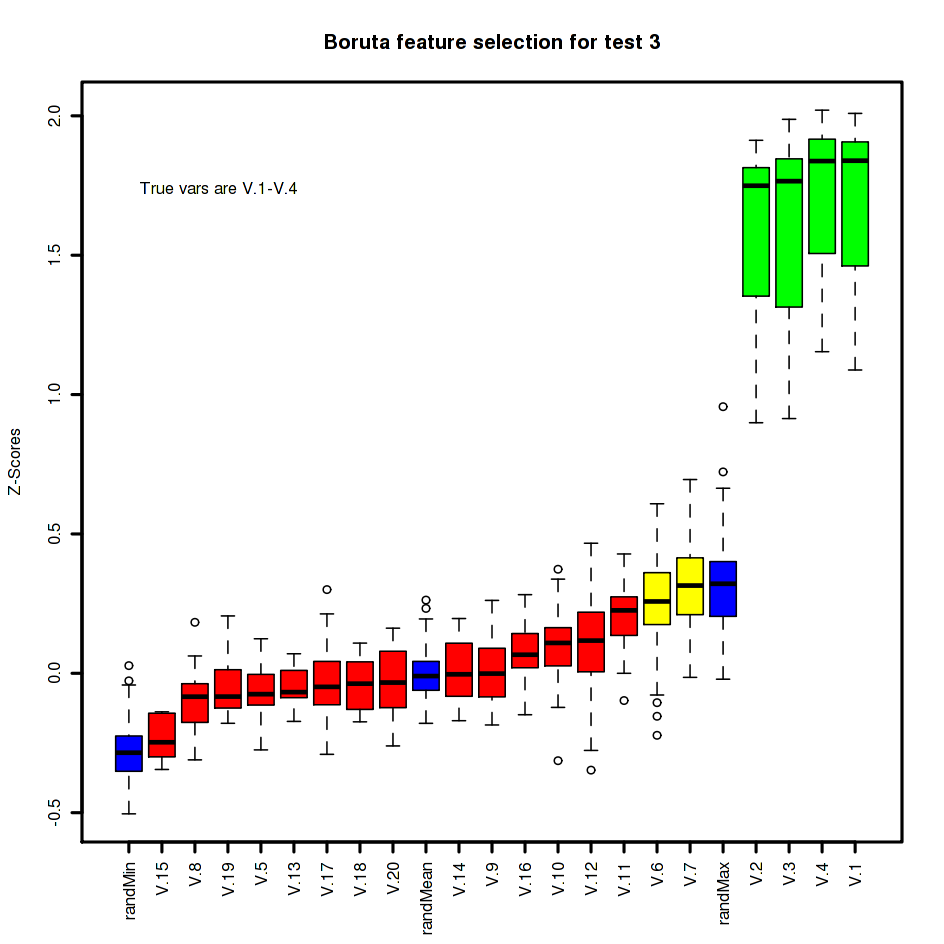
Test 4: Simple test of non-linear combination
For a spectacular fail of the Boruta approach we will have to consider a classification in the hyperplane of the four variables. For this simple example, we simply count if there are an even or odd number of positive values among the first four variables:
## 4. Simple test of non-linear combination
y.4 <- factor(rowSums(x[, 1:n.dep] >= 0) %% 2)
b.4 <- Boruta(x, y.4, doTrace = 2)
print(b.4)
make.plots(b.4, 4, n.dep)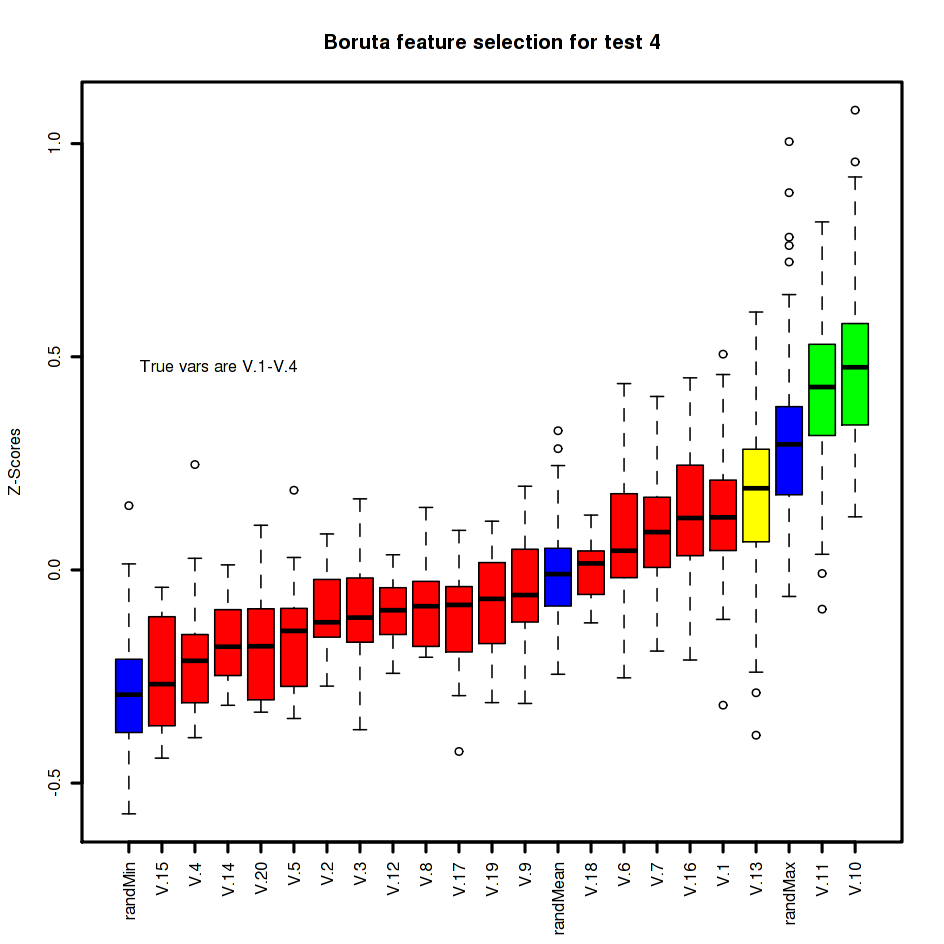
Ouch. The package rejects the four known significant variables. It is too hard for the random forest approach. Increasing the number of observations to 1,000 does not help though at 5,000 observations Boruta identifies the four variables right.
Limitations
Some limitations of the Boruta package are worth highlighting:
It only works with classification (factor) target variables. I am not sure why: as far as I remember, the random forest algorithm also provides a variable significance score when it is used as a predictor, not just when it is run as a classifier.
It does not handle missing (
NA) values at all. This is quite a problem when working with real data sets, and a shame as random forests are in principle very good at handling missing values. A simple re-write of the package using the party package instead of randomForest should be able to fix this issue.It does not seem to be completely stable. I have crashed it on several real-world data sets and am working on a minimal set to send to the authors.
But this is a really promising approach, if somewhat slow on large sets. I will have a look at some real-world data in a future post.
Citation
@online{2010,
author = {},
title = {Feature Selection: {All-relevant} Selection with the {Boruta}
Package},
date = {2010-11-15},
url = {https://www.cybaea.net/Journal/2010/11/15/Feature-selection-All-relevant-selection-with-the-Boruta-package.html},
langid = {en-GB-oxendict}
}